In DirectX 12, before a shader can read a texture, a descriptor must exist somewhere on the GPU that points to it. These descriptors do not live scattered in arbitrary memory — they live inside a structure called a descriptor heap, and the GPU expects them to be laid out in a specific way. This post explains how we manage descriptor heaps in our engine, what a descriptor block is, and why contiguous allocation matters when binding multiple textures to a material.
What is a Descriptor Heap?
A descriptor heap is a GPU-side array of fixed-size entries. Each entry is a descriptor: a small opaque blob that tells the GPU how to interpret a resource, whether it is a texture, a constant buffer, a sampler, or something else. DirectX 12 exposes four heap types:
- CBV_SRV_UAV — constant buffers, shader resource views, unordered access views
- Sampler — texture sampler states
- RTV — render target views (CPU-only)
- DSV — depth-stencil views (CPU-only)
Heaps flagged as shader-visible are the ones that actually get bound to the GPU pipeline. The GPU reads from them directly during rendering. CPU-only heaps are staging areas used to fill in descriptors before copying them to a shader-visible heap.
Our engine creates one heap per type at startup. The CBV_SRV_UAV heap is the largest, since it holds all texture views used during rendering:
m_DescriptorHeapMap[D3D12_DESCRIPTOR_HEAP_TYPE_CBV_SRV_UAV] =
new DescriptorHeap(device, D3D12_DESCRIPTOR_HEAP_TYPE_CBV_SRV_UAV, 4096 * 8);DescriptorHeap: The Wrapper
The DescriptorHeap class wraps an ID3D12DescriptorHeap and manages allocation through a sorted free-list. A free-list is a list of contiguous ranges that are not yet in use, ordered by their start index. When something needs descriptors, we search the list for a range large enough to fit the request.
The core allocator uses a first-fit strategy: it walks the free-list until it finds a range with enough capacity, carves out the requested count from the front of that range, and returns a DescriptorHeapBlock pointing to those slots.
DescriptorHeapBlock* DescriptorHeap::allocateBlock(uint32_t count)
{
for (auto it = m_freeList.begin(); it != m_freeList.end(); ++it)
{
if (it->count < count) continue;
const uint32_t start = it->start;
if (it->count == count)
m_freeList.erase(it);
else
{
it->start += count;
it->count -= count;
}
m_blocks[start] = DescriptorHeapBlock(this, start, count, m_genNumber);
return &m_blocks[start];
}
return nullptr;
}Freeing a block inserts the range back into the free-list in sorted order, then coalesces it with any adjacent free ranges to avoid fragmentation over time.
DescriptorHeapBlock: A Contiguous Slice
A DescriptorHeapBlock represents a contiguous slice of the heap. It stores the base index, the count, and a back-pointer to its parent heap. From there, any slot can be addressed by offset:
D3D12_CPU_DESCRIPTOR_HANDLE DescriptorHeapBlock::getCPUHandle(uint32_t slot) const
{
assert(slot < m_size && "Slot index out of block range");
return m_heap->getCPUHandle(m_baseIndex + slot);
}Blocks also carry a generation number. This is a small counter that increments each time a new block is allocated from the same heap position. It makes it possible to detect stale handles that still reference a block that has since been freed and reused.
On construction, the block runs a contiguity assertion in debug builds. It walks every slot and verifies that each CPU pointer is exactly one descriptor stride apart from the previous one. This catches any case where heap corruption or a misconfigured allocation would produce non-contiguous memory — something that would silently fail later during rendering.
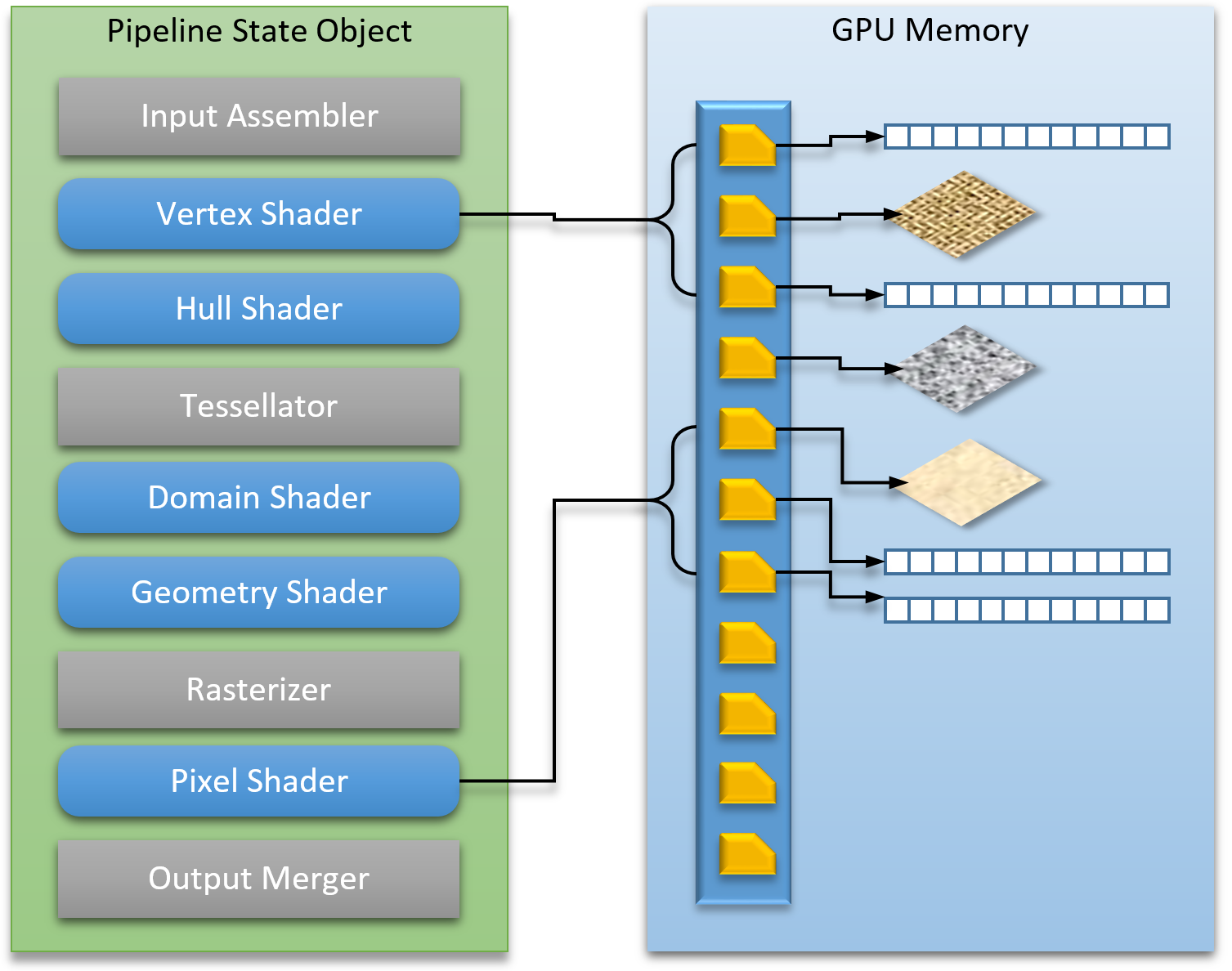
Why Contiguous Descriptors Matter for Materials
When a material binds multiple textures to a shader — albedo, normal map, roughness, metallic, and so on — DirectX 12 does not want each descriptor handed to the GPU one by one. Instead, the API is designed around descriptor tables: a single root parameter that points to a base descriptor in the heap, followed by a count. The GPU reads each texture by adding an offset from that base.
This means all textures for a draw call must be in consecutive heap slots. If they are scattered around, the GPU would read garbage between them. The contiguous block allocation in our heap wrapper exists precisely to guarantee this. When a material needs five texture slots, it calls allocateBlock(5), gets back a single block, and places each texture descriptor at slot 0 through 4. The root signature then receives just the base handle and the count.
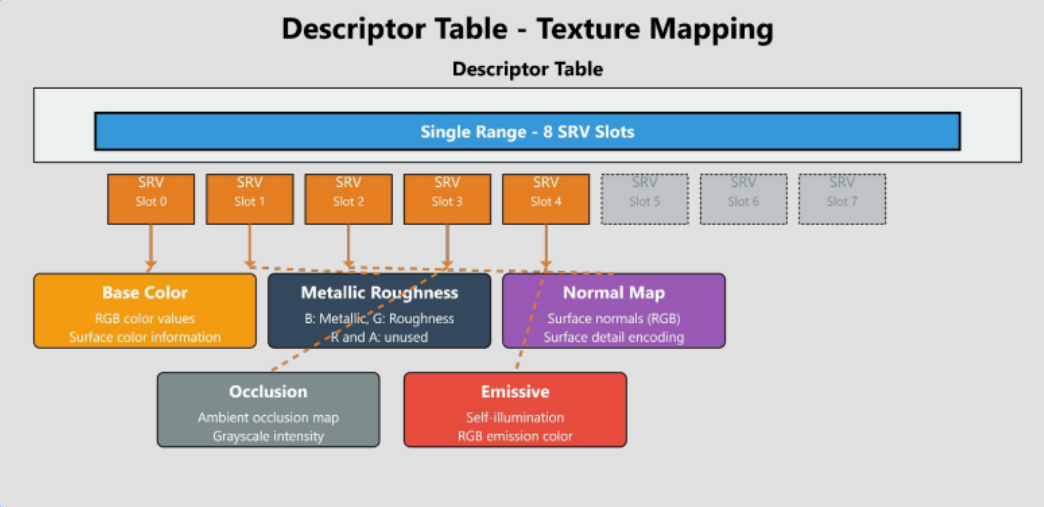
Attempting to bind non-contiguous descriptors would require either multiple root parameter slots (wasting root signature space) or an extra copy pass to pack them together before each draw — both of which add overhead. Allocating a contiguous block upfront avoids that entirely.
DescriptorHandle: The Return Type
Callers do not interact with raw heap indices. Instead, allocate() and getHandle() return a DescriptorHandle, which bundles together:
- cpu — the CPU-side pointer used to write the descriptor
- gpu — the GPU-side pointer passed to SetGraphicsRootDescriptorTable
- handle — an opaque integer encoding the index and generation for later freeing
- block — a pointer back to the owning block for validation
struct DescriptorHandle {
D3D12_CPU_DESCRIPTOR_HANDLE cpu{};
D3D12_GPU_DESCRIPTOR_HANDLE gpu{};
UINT handle{ 0 };
const DescriptorHeapBlock* block{ nullptr };
constexpr bool IsValid() const { return cpu.ptr != 0; }
constexpr bool IsShaderVisible() const { return gpu.ptr != 0; }
};
Having both CPU and GPU handles in the same struct means a caller can write the descriptor (using the CPU handle) and then immediately bind it to the pipeline (using the GPU handle) without going back to the heap or doing any extra lookup.
Deferred Release
GPU resources cannot be freed the instant the CPU decides they are no longer needed. The GPU may still be executing a frame that references those descriptors. Freeing them immediately would corrupt an in-flight draw.
We handle this with deferred release. When a descriptor is no longer needed, instead of calling free() directly, the caller goes through defferDescriptorRelease(). This queues the handle alongside the current frame number. During preRender() at the start of each frame, we check which queued entries belong to frames that have already completed on the GPU, and only then return those descriptors to the heap.
void ModuleDescriptors::preRender()
{
UINT lastCompletedFrame = app->getModuleD3D12()->getLastCompletedFrame();
for (int i = 0; i < m_defferedDescriptors.size(); ++i)
{
if (lastCompletedFrame > m_defferedDescriptors[i].frame)
{
m_DescriptorHeapMap[CBV_SRV_UAV]->free(m_defferedDescriptors[i].handle);
m_defferedDescriptors[i] = m_defferedDescriptors.back();
m_defferedDescriptors.pop_back();
}
else ++i;
}
}This pattern is straightforward to implement and keeps descriptor lifetime tied to actual GPU completion rather than CPU-side logic, which is where frame-in-flight bugs tend to originate.
Summary
The descriptor heap system in our engine builds up in three layers. DescriptorHeap owns the GPU heap and manages a sorted free-list for allocation and coalescing. DescriptorHeapBlock represents a contiguous slice of that heap, exposes per-slot handles, and validates layout in debug builds. DescriptorHandle wraps everything a caller needs into a single struct with no further lookups required.